
Contents
事前準備
①まず、Microsoft Azure Machine Learning Studioを使うために、Microsoftのアカウントを作成しておいてください。
②次に、Microsoft Azureのアカウントを作成します。
③サインアップしたら、下図のように、Expreimentsをクリックしてください。
以上で事前準備は完了です。
なお、以下の記事を読むのが面倒、とにかく分かりやすく基本の使い方を見たい!という方は、私の記事を読むよりもまず以下のTutorialを見るのが一番です。
Hello World Experimentsの作成
Hello Worldとはいえ、あまりなにも処理が無いモデルだとAzure Machine Learningの素晴らしさが分からないかと思いますので車両価格予測モデルの作成を行っていきます。
なお、以下の本のPart1:Chapter2の一部を参考にしています。丁寧で非常に分かりやすいです。
新しいExperimentsの作成
①+newをクリックします。
②blankを選択します。
![]()
③experiment名を入力します。
データの準備
①まずは元々用意されているデータセットを使います。今回は、Automobile price data(Raw)をドラッグ&ドロップします。
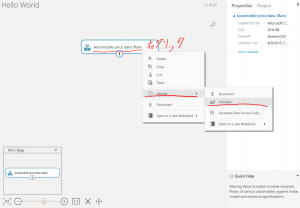
②データセットの中身を確認したい場合は、右クリック→dataset→visualizeで確認できます。
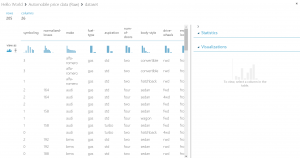
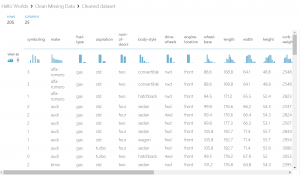
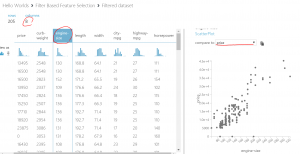
メーカー名やエンジンタイプ、サイズ等、205行26列のデータが格納されています。
③ちなみに、特定のデータの分布を見たい場合は、列を選択することで表示できます。例えば、エンジンサイズを確認する場合、以下のように選択します。(累積分布や確率密度分布も確認できますし、軸を対数に変更することもできます)
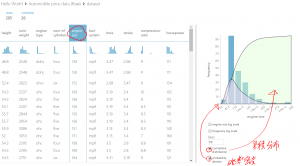
また、ViewAsをクリックすると、Box Plotを表示させることも可能です。

試しに、馬力vs値段をプロットしてみると、以下のように相関が簡単に確認できます。
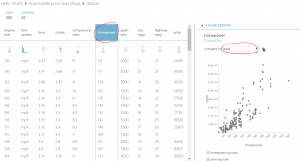
データの前処理
①欠損データを含むデータの前処理
Automobile price data(Raw)には、欠損データが含まれています。Normalized -lossesというColumnを見ると、41の欠損データがあります。
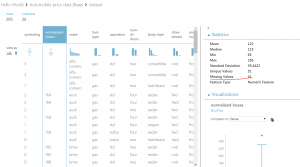
②欠損データを除くために、データを加工していきます。
Data Transformation→Manipulation→Select Columns in Datasheetを選択し、ワークシート上に配置します。
そのあと、”Automobile price data(Raw)”の出口portから、”Select Columns in Datasheet”の入り口portを接続します。
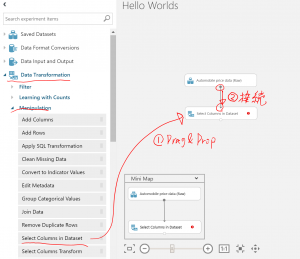
③Select Column in Datasetをクリックし、”Launch column selector”をクリックします。
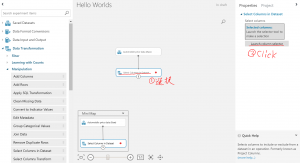
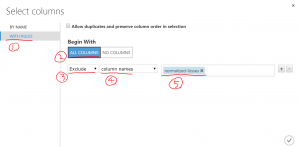
④以下の流れで、”normalized-losses”をExclude(除外)します。
設定が完了すると、下図のように除外されたColumnが表示されます。
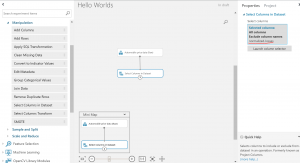
※各モジュールは、ダブルクリックすることでコメントを記載することが可能です。

⑤”normalized-losses”以外にも欠損データがあります。
欠損データを取り扱う場合は、大きく分けて1.前述のように欠損データを含むデータを削除する、2.欠損データを補間することが考えられますが、ここでは欠損データに0を代入していきます。(2については、欠損データを補間する方法もあります。)
Data Transformation→Manipulation→Clean Missing Dataを選択し、ワークシート上に配置します。設定は、defaultのままで大丈夫です。(欠損値に0を代入します)
そのあと、”Select Columns in Datasheet”の出口portから、”Clean Missing Data”の入り口portを接続します。
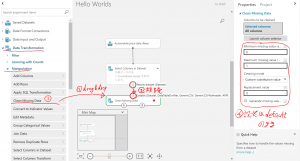
⑥これで事前処理は終了です。Runをクリックしてください。
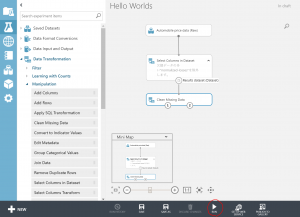
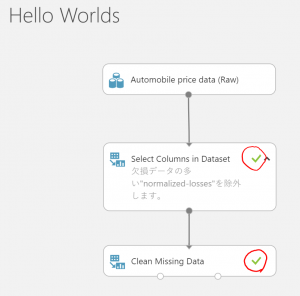
Runが完了すると、緑色のチェックが表示されます。これで、データの前処理は完了です。
前処理後のデータを見たい場合は、下図のようにCleaned datasetをvisualizeしてみましょう。
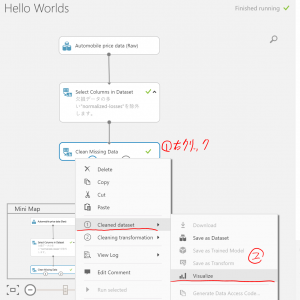
“normalized-losses”の列が除外され、欠損データが0で置き換えられていることが確認できます。
車体価格予測に使用する説明変数の選択
①車体価格予測に使用する変数(特徴)を選択していきます。
下図のように、price(車両価格)に影響しそうな説明変数を、相関係数を元に求めます。(Features scoring methodを”Mutual Information”にする必要があります)
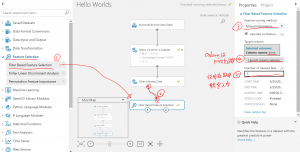
詳細は、こちらのリンクをご参照ください。
②Filtered Based Featureを右クリックし、Visualizeすると、メーカー名や相関係数を元に決定する場合、エンジンサイズや馬力等、概ね価格に影響しそうな変数を選択できていそうです。(ただ、相関係数で絞った場合、メーカーやbody-styleといった、価格に影響し得る要因に対して取りこぼしもあります。)
学習モデルの作成
いよいよ学習モデルを作成していきます。
①まず、下図の流れで前処理後のデータを、トレーニングデータとテストデータに分割します(トレーニングデータ:80%、テストデータ:20%)。
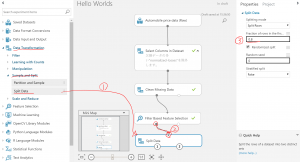
Row(行)で区切り、上から80%分をport1に出力します。
(各portをvisualizeで確認し、port1が164行、port2が41行であることを確認してください)
②回帰モデルを選択します。まずは、Linear Regressionモデルを試してみましょう。
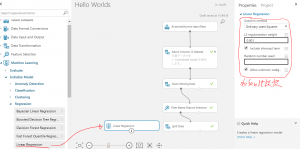
③ワークシート上にTrain Modelを設置し、②で選択した回帰モデルとトレーニングデータ(トレーニングデータはport1です)を接続します。
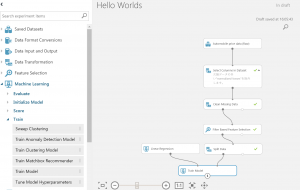
④ここまでの設定を使って、モデルをRunさせてみましょう。
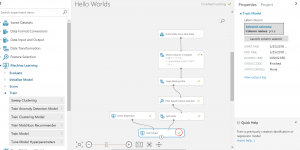
学習モデルの検証
前ステップで作成したモデルを使って、テストデータを使った精度検証を行っていきます。
①Scoreモデルをワークシート上に置き、テストデータ(Splitモジュールのport2)を接続します。
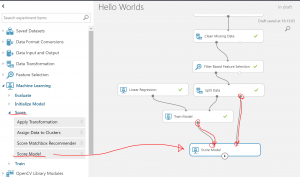
モデルをRunしてスコアを求めます。
②Scoreの評価を確認するため、Evaluationモジュールをワークシート上に設置し、Scoreモジュールの出口portと接続します。

モデルをRun します。
③Evaluationを右クリックして、結果をvisualizeします。
決定係数が低い場合は、予測モデルを変えたり、説明変数を変えてみてください。
特に、今回メーカー名やbody style等、価格に影響を与えるはずの要素が抜けていますので、メーカー毎にモデルを変える等工夫してみてください。

コメント